Technology Asset Static Data
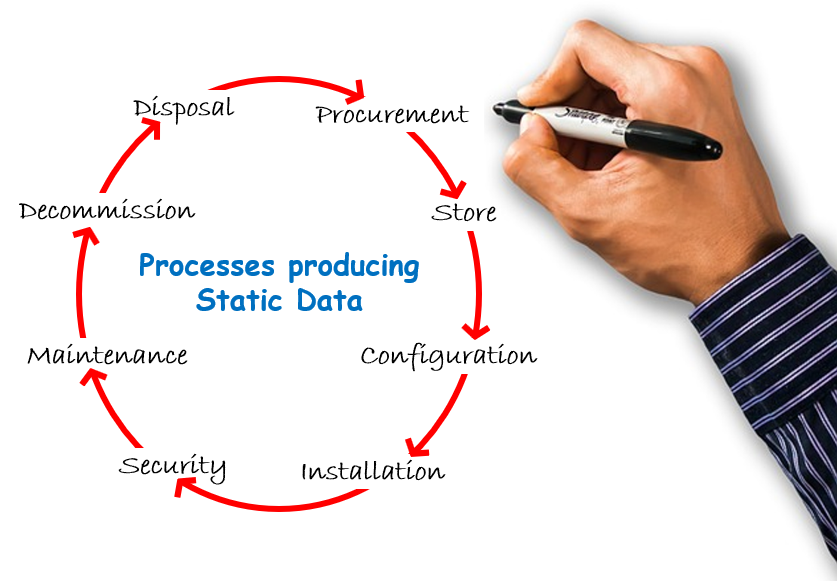
Static Data can be any type of data that is not readily accessible by a downstream process.
Data that is technical or highly variable, like usage metrics is usually Discoverable Data, although this often then just gets imported to a Static data report. To avoid becoming Static Data the discovery tool must provide consistent data to all integrated consumers.
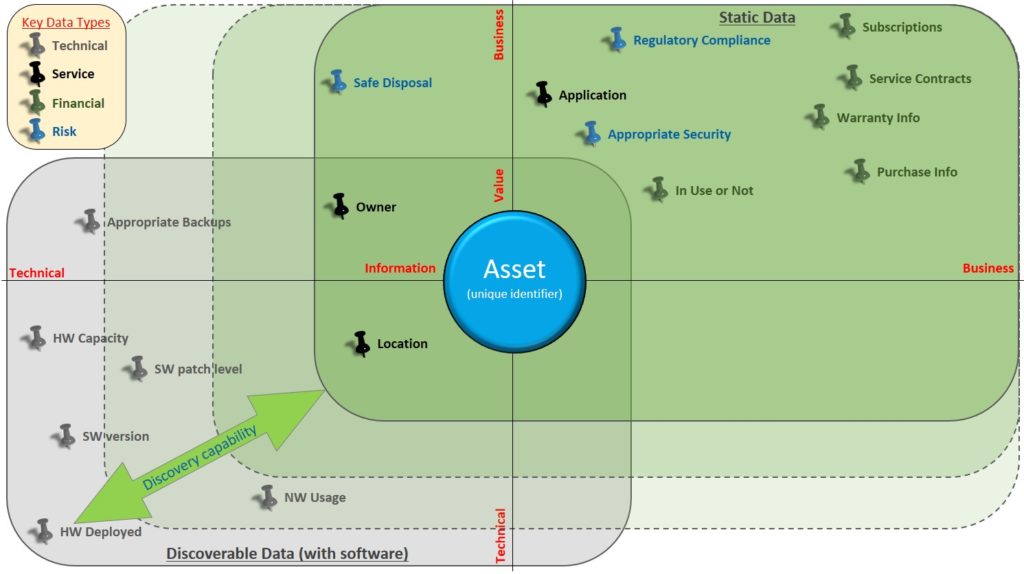
Attributes that were expected to be fixed or have limited subsequent use are much more likely to be stored as Static Data. This valuable knowledge offers increasing value in organisations looking to improve their service experience or where this is a focus on optimisation, but only if you can access it effectively.
As you can see here, a large amount of higher value information is typically Static Data, when it comes to looking for information that will help you change your Service, Risk, or Cost dynamics.
Static Asset Data Challenges
Without consistent processes and tools for managing asset related data across diverse teams, they each develop their own approach, and will each have at least one asset inventory containing Static Data, which will have no local or inter team validation, and be developed for use only within each team. More than 50% of Static Data is typically wrong, either due to poor initial data entry or by being out of date.
The larger an organisation, the bigger the Static Data issue becomes, considering the number of teams involved throughout the assets lifecycle
Building an asset repository from Static Data is traditionally a “one time activity”, often repeated and in parallel with other people trying to achieve something similar for their own purpose. It relies on lookups in spreadsheets to link to information about a set of devices, often using the device serial to form the data join, and the final output is compromised by the quality issues already discussed.
You may understand the risks with a inventory you have built yourself for a specific one time purpose, but if that inventory is used to seed a company CMDB, then others will not expect the data to be inaccurate.
Each requirement to pull extra or additional Static Data into your current inventory will add significant complexity. You will increasingly find that the much of your desired Static Data will remain inaccessable, as it was never stored with integration in mind.
The Data MetaMorph Approach
Our Integrated Data & Info Analysis (IDIA) service model uses our proprietary Unstructured Data Asset Management (UDAM) software framework to take into account the reality of Static Data, in that each team will store data in their own format for their own purpose, and that a great deal of that data may be inaccurate, out of date or both.
To overcome the issue of duplicate or missing assets, we have developed an enhanced asset reconciliation approach, building a picture of metadata characteristics that enable us to find Name and Serial for each device automatically or through prompted questions where conflicts arise.
All source data is parsed into a consistent format, before it is imported into a device journal. As a result, once the join has been established through reconciliation, valuable knowledge is now accessible from a practically unlimited number of data sources. We use a configurable Static Data weighting process to populate knowledge about each asset from the most trustworthy sources where available.
Perhaps most importantly, we can update the results to reflect change at any point by importing newer or additional data.
Please see the attached Gaining Asset Knowledge Datasheet for more information on this service